von Jan Coenen
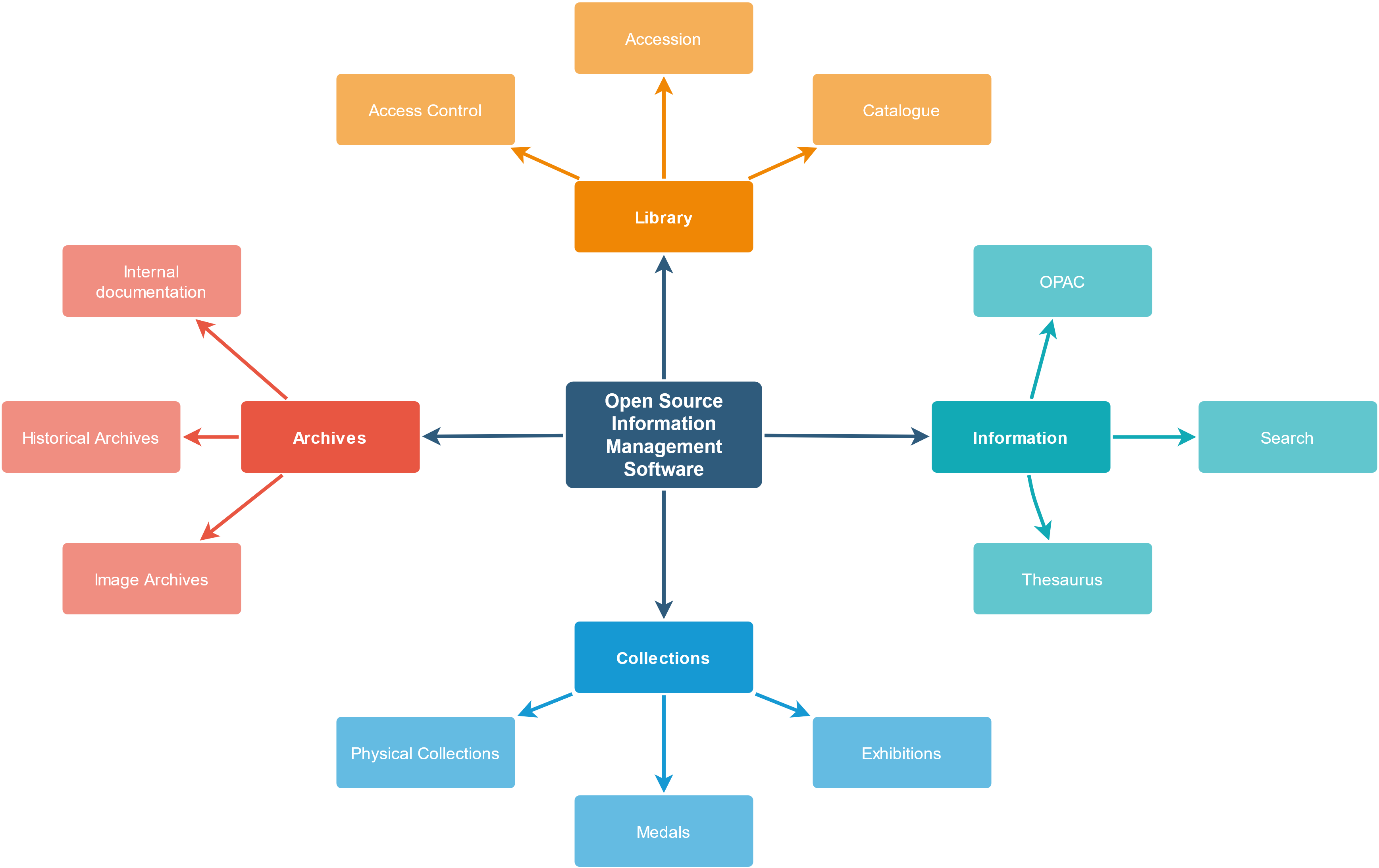
Der Markt für Open Source-Lösungen im Bereich der Bibliotheks- und Informationsdienstleistungen hat sich in den letzten Jahren stark und vielfältig ausdifferenziert. Dabei fällt allerdings auf, dass viele Systeme auf den ersten Blick die gleichen Funktionen anbieten. Erst bei genauerer Betrachtung fällt auf, dass sich die Lösungsansätze vor allem darin unterscheiden, ob sie tief oder breit aufgestellt sind. Tiefe Lösungsansätze konzentrieren sich darauf, einen Informationsbestand, sowie alle dazu anfallenden Handlungen, möglichst exakt wiederzugeben. Breite Ansätze hingegen versuchen, möglichst viele Informationsbestände miteinander in Verbindung zu bringen.
Ein Beispiel für eine tiefe Open Source-Lösung ist etwa Koha für Bibliotheken. Sämtliche bibliothekarische Workflows, von der Erwerbung, über den Leihverkehr, das Fernleihwesen und die Nutzerkontensteuerung, sind in Koha abgedeckt. Für die Katalogisierung von allem, was kein bibliothekarischer Bestand im eigentlichen Sinn ist, eignet es sich jedoch nicht. Da im vorliegenden Beispiel allerdings aufgrund der sehr unterschiedlichen Bestände, die sowohl als Bücher, Zeitschriften, Archivalien aber auch physische Objekte vorliegen, eine breite Lösung angewandt werden muss, wurde zunächst der Markt hierfür sondiert. Nach einer Demophase, in der die Vorzüge und Nachteile verschiedener Programme, wie Omeka, Collection Space, FOLIO und Collective Access herausgearbeitet wurden, fiel die Wahl auf Collective Access. Dieses konnte sich, vor dem Hintergrund ähnlicher Grundfunktionalität aller Programme, vor allem aufgrund der guten Dokumentation sowie der relativ leichten Datenmigration aus dem bestehenden System heraus durchsetzen.
Bevor diese Migration jedoch stattfinden kann, muss zunächst eine Datenkonsolidierung stattfinden. Bislang gibt es in der Einrichtung drei Bestände, die die verschiedenen Sammlungsgruppen voneinander abgrenzen. Der Gesamtbestand unterteilt sich so auf Archiv, Bibliotheken und Sammlungen. Ziel des Wechsels auf ein breit angelegtes System ist es auch, diese Bestände der Einrichtung miteinander in Verbindung zu bringen und, unter Berücksichtigung der jeweiligen Eigenheiten der Bestände, eine gemeinsame Ontologie zu finden, sodass bei einer Suchanfrage alle Bestandsgruppen berücksichtigt werden können.
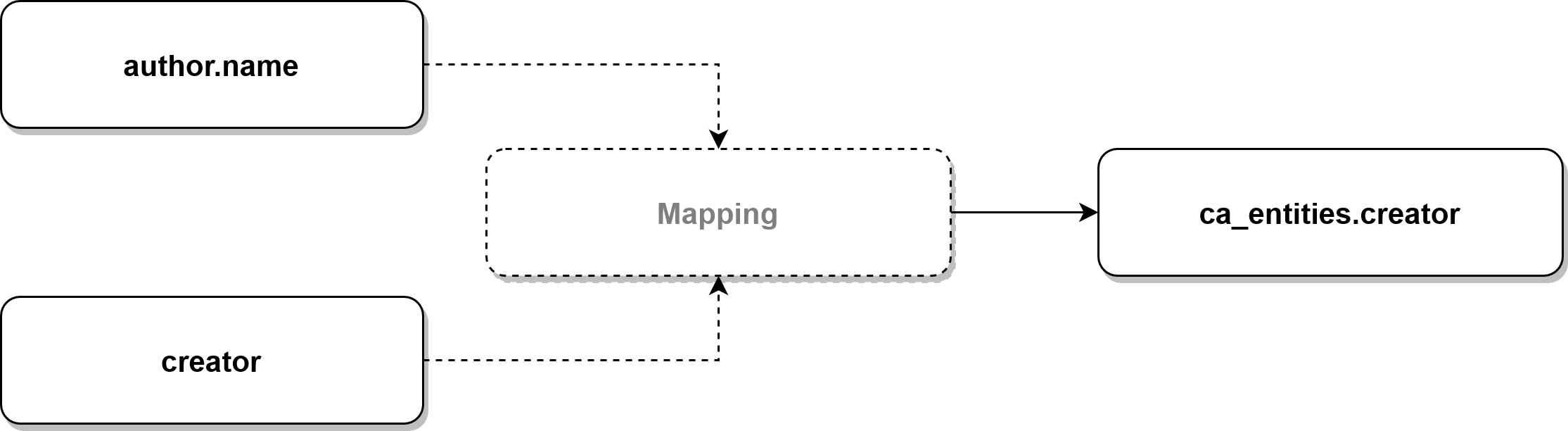
Hierzu müssen vorhandene Bestandsmetadaten abgeglichen und eine gemeinsame Bezeichnung gefunden werden. Sieht man sich beispielsweise den Erschaffer eines Werkes an, so weisen Bibliothek auf der einen, sowie Archiv und Sammlung auf der anderen Seite, unterschiedliche Metadatenfelder auf. In der Bibliothek ist es „author.name“, in den anderen Bereichen „creator“. Mithilfe eines Mappingdokumentes können diese beiden Felder im neuen System zu einem einzelnen Feld verbunden werden.
Sobald die Datenmigration abgeschlossen ist, kann das neue System genutzt werden. Durch den Erwerb einer Open Source-Lösung und die Verwendung einer eindeutigen Sprache sind die Bestände der Einrichtung nicht nur zukunftssicher geworden, sondern können auch anschaulich dargestellt und somit besser kommuniziert werden. Ebenso bieten sich durch die Funktionen der neuen Lösung Nachfolgeprojekte, wie etwa die Veröffentlichung eines Web-OPAC oder auch die Bereitstellung von Digitalisaten zur Nutzung an.
Projektzeitraum: September 2020 bis Februar 2021
Projektbetreuer*in: Dr. Andreas Weber
Kontakt: jcoenen87@gmail.com